ClickHouse解析
clickhouse简介
“When we released ClickHouse, we had only one goal in mind, to give people the fastest analytical DBMS in the world.” — Alexey Milovidov
ClickHouse提出背景
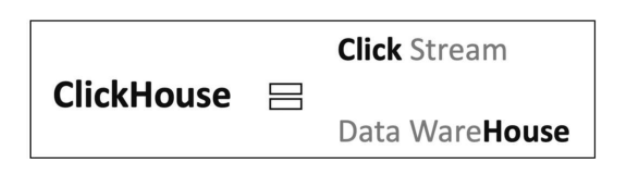
初始设计目标是服务于Yandex.Metrica.这是一款web流量分析工具.在采集数据时,一次页面点击(click),就会产生一条记录,clickhouse就是基于这样的点击事件流(Click Stream)的数据仓库(Data WareHouse).
clickhouse适用场景
各类数据分析类场景(BI领域等)
clickhouse不适用的场景
- 不支持事务
- 已经有计划去实现在单个事务中支持大规模数据的insert.
- 完整的ANSI SQL Transaction不在roadmap中.
- 不擅长根据主键按行粒度进行查询(虽然支持),故不应该把ClickHouse当作Key-Value数据库使用.
- 不擅长按行update delete(虽然支持).
特性
- DDL,DML,权限控制,数据备份与恢复,分布式
- 列式存储与数据压缩(降低IO 向量化执行SIMD)
架构
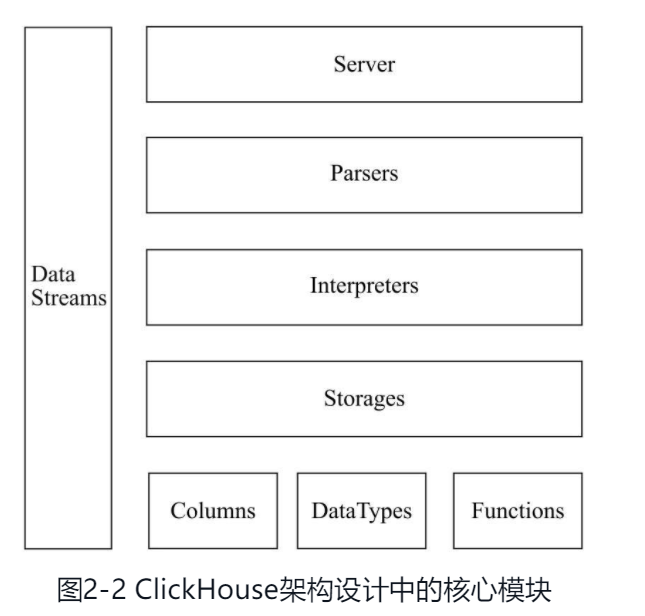
- server 在接入层 ClickHouse 支持多种接口:
- Reust HTTP 方式.
- ClickHouse Native,通过 ClickHouse 协议 TCP 的方式接入,性能会更好。
- 其他 mysql等.
- parser 解析器,解析器创建AST.
- Interpreter 解释器,从AST创建查询执行流水线.
- IBlockInputStream接口总共有60多个实现类,它们涵盖了ClickHouse数据摄取的方方面面。这些实现类大致可以分为三类:第一类用于处理数据定义的DDL操作,例如DDLQueryStatusInputStream等;第二类用于处理关系运算的相关操作,例如LimitBlockInput-Stream、JoinBlockInputStream及AggregatingBlockInputStream等;第三类则是与表引擎呼应,每一种表引擎都拥有与之对应的BlockInputStream实现,例如MergeTreeBaseSelect-BlockInputStream(MergeTree表引擎). 类似于算子.以 insert为例.
- Storages
- datatype 数据的序列化和反序列化.
mergetree
表引擎是clickhouse设计中的特色.clickhouse存储层有多种表引擎.最常用最基本的是mergetree.
基本数据类型
column field
内存中的一列数据由一个column对象表示.如果需要操作单个具体的数值则需要使用field对象,表示一个单值.
field类似union,可以存储不同类型的值,但在任何时候只有一个值可以被存储.
1
2
3
4
5
6
7
8
9
10
11
12
13/// src/Core/Field.h
class Field
{
...
std::aligned_union_t<DBMS_MIN_FIELD_SIZE - sizeof(Types::Which),
Null, UInt64, UInt128, Int64, Int128, Float64, String, Array, Tuple, Map,
DecimalField<Decimal32>, DecimalField<Decimal64>, DecimalField<Decimal128>, DecimalField<Decimal256>,
AggregateFunctionStateData,
UInt256, Int256
> storage;
...
}
- 根据数据类型不同,column有不同的实现对象.以
ColumnInt8为例
1 | |
block
clickhouse的内部数据操作是面向block对象的.本质是由数据对象,datatype 与列名称组成的三元组(column datatype 列名称字符串).Column提供了数据的读取能力,而DataType知道如何正反序列化,在具体的实现过程中,Block并没有直接聚合Column和DataType对象,而是通过ColumnWithTypeAndName对象进行间接引用。
1 | |
mergetree的创建
engine=MergeTree();
- partition by 分区键
- order by 排序键
- primary key 主键
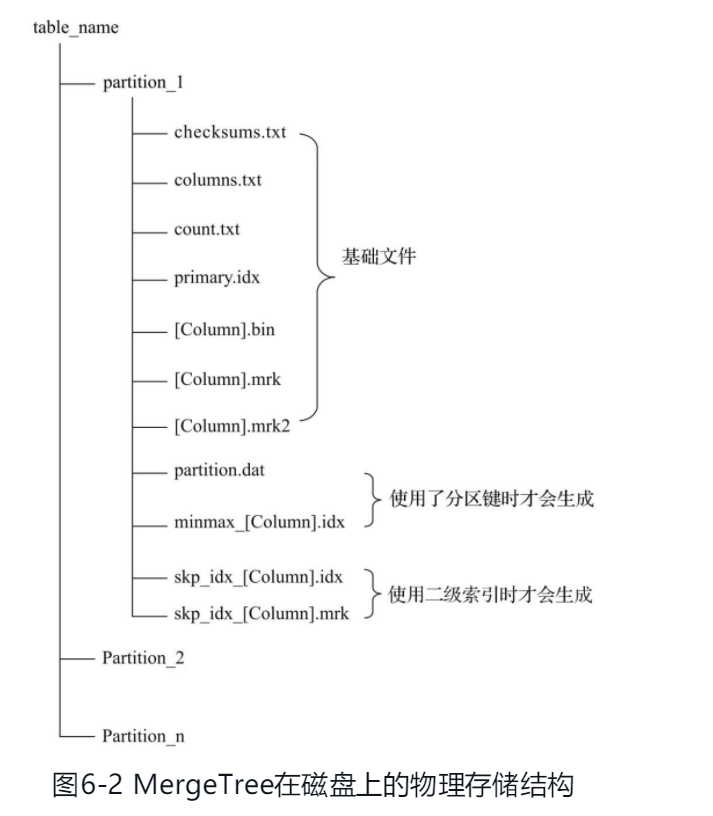
partition 分区目录 属于相同分区的数据最终会被合并到同一个分区目录,而不同分区的数据不会被合并在一起.
checksums 校验文件 存储了各类文件的size和size的哈希值 用于校验文件的完整性和正确性
columns 列信息 明文存储

计数文件 记录当前数据分区目录下的数据总行数
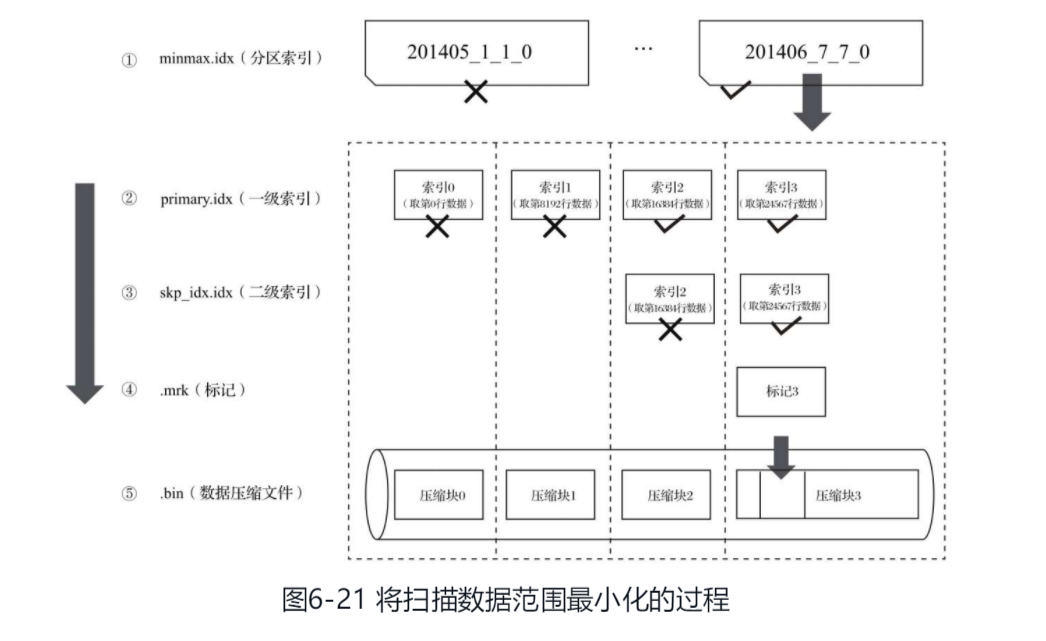
primary.idx 一级索引文件 存放稀疏索引
[column].bin 数据文件
[column].mrk 列字段标记文件 保存了bin文件中的数据偏移量.首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据
mrk2 如果采用了自适应大小的索引间隔 标记文件为mrk2
partition.dat minmax_[column].idx 如果使用了分区键 则会生成 例如EventTime字段对应的原始数据为2019-05-01、2019-05-05,分区表达式为PARTITION BY toYYYYMM(EventTime)。partition.dat中保存的值将会是2019-05,而minmax索引中保存的值将会是2019-05-012019-05-05。
skp_idx 二级索引
数据分区
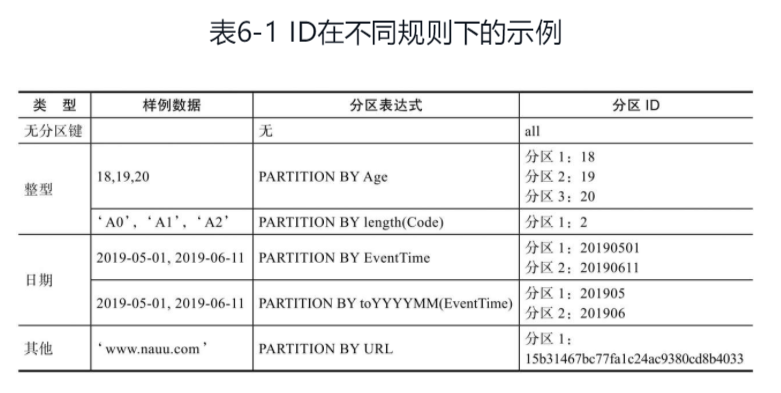
在ClickHouse中,数据分区(partition)是针对本地数据而言的
分区规则:
- 不指定分区键 默认所有数据会被写入all分区
- 分区键为整型 直接按照整型的字符形式输出 作为分区id的取值
- 日期类型 按照yyyymmdd进行格式化后的字符形式输出
- 其他类型 hash之后的值作为分区id的取值
数据在写入时,会对照分区ID落入相应的数据分区
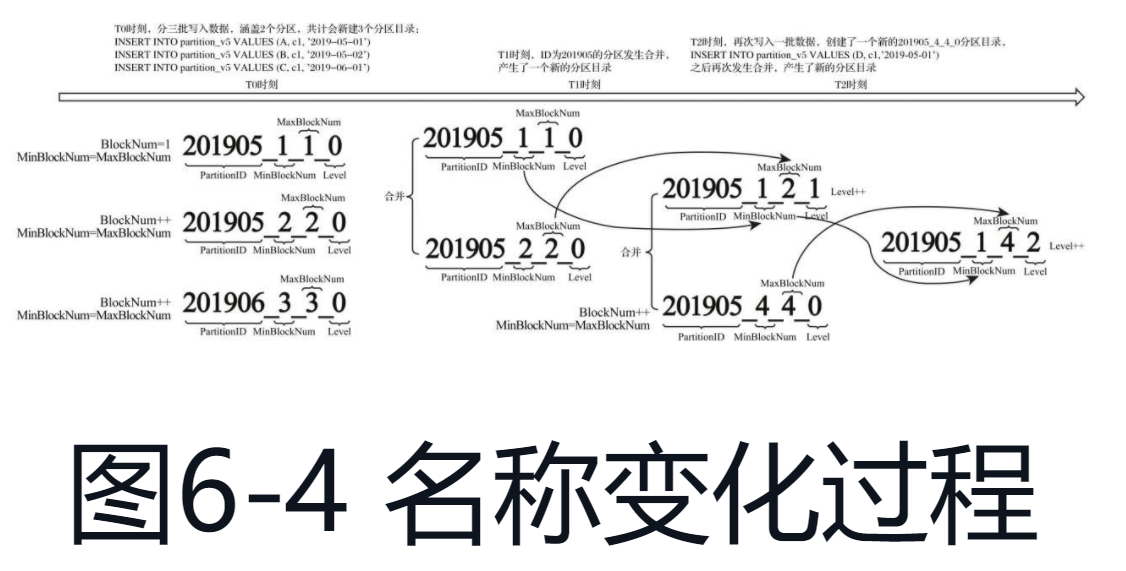
分区目录命名

分区目录合并
MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。伴随着每一批数据的写入(一次INSERT语句), MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。
合并规则:
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。
- Level:取同一分区内最大Level值并加1。
一级索引
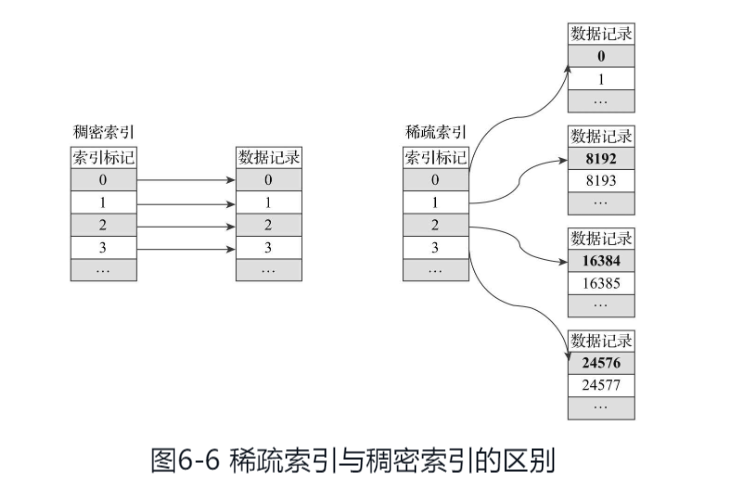
由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快。
ClickHouse对主键索引的定义和传统数据库的定义稍有不同,它的主键索引没用主键去重的含义,但仍然有快速查找主键行的能力。
ClickHouse的主键索引存储的是每一个granularity中起始行的主键值.
索引查询过程
MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段即是一个MarkRange。
三个步骤:
- 生成查询条件区间
- 递归交集判断 如果不存在交集 剪枝算法优化整段markrange 存在交集将此区间进一步拆分成8个子区间,如果存在交集且步长小于8 则记录markrange返回.
- 合并markrange区间并返回
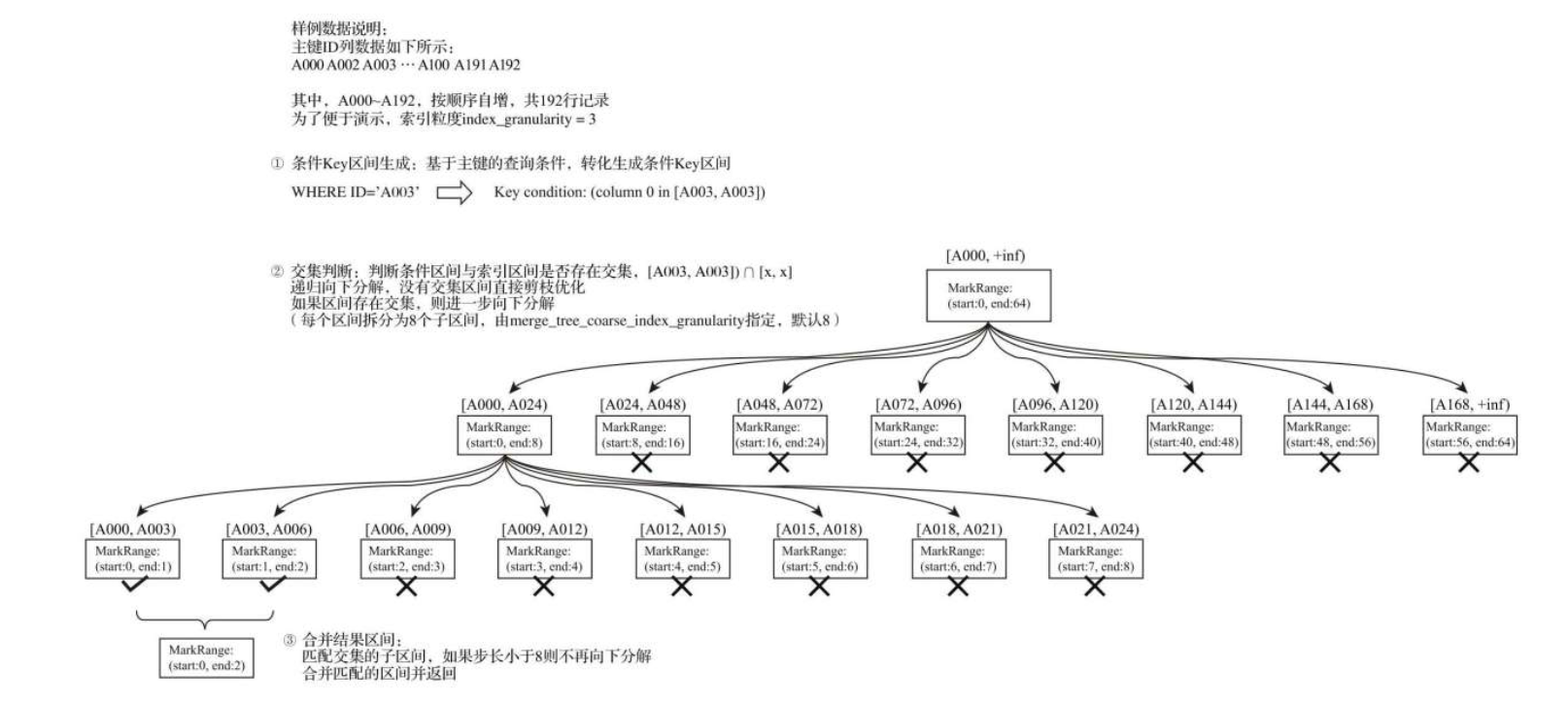
因为MarkRange转换的数值区间是闭区间,所以会额外匹配到临近的一个区间
二级索引
granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
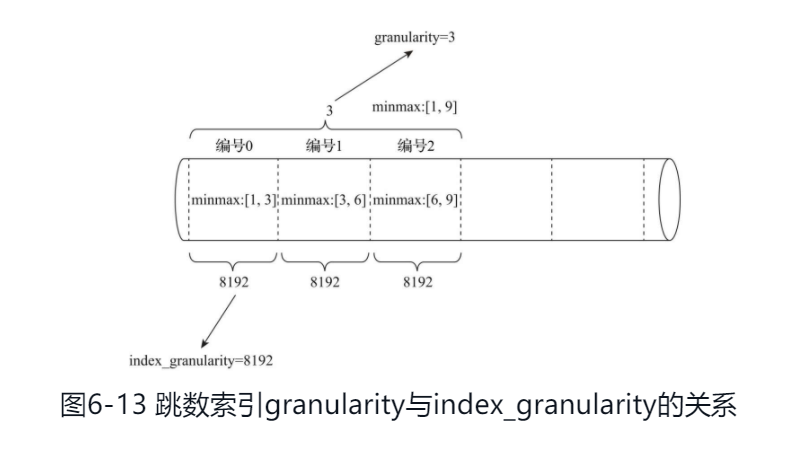
跳数索引:
- minmax 记录了一段数据的最小最大值
- set 完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制,

数据存储

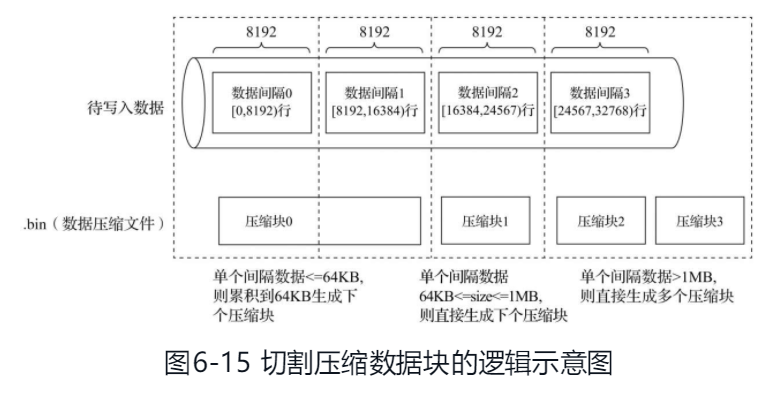
.bin文件中引入压缩数据块的目的至少有以下两个:其一,虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率,但数据的压缩和解压动作,其本身也会带来额外的性能损耗。所以需要控制被压缩数据的大小,以求在性能损耗和压缩率之间寻求一种平衡。其二,在具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围。
数据标记
每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息。
一行标记数据使用一个元组表示,一个index_granularity对应一行标记数据. 元组内包含两个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;以及将该数据压缩块解压后,其未压缩数据的起始偏移量。
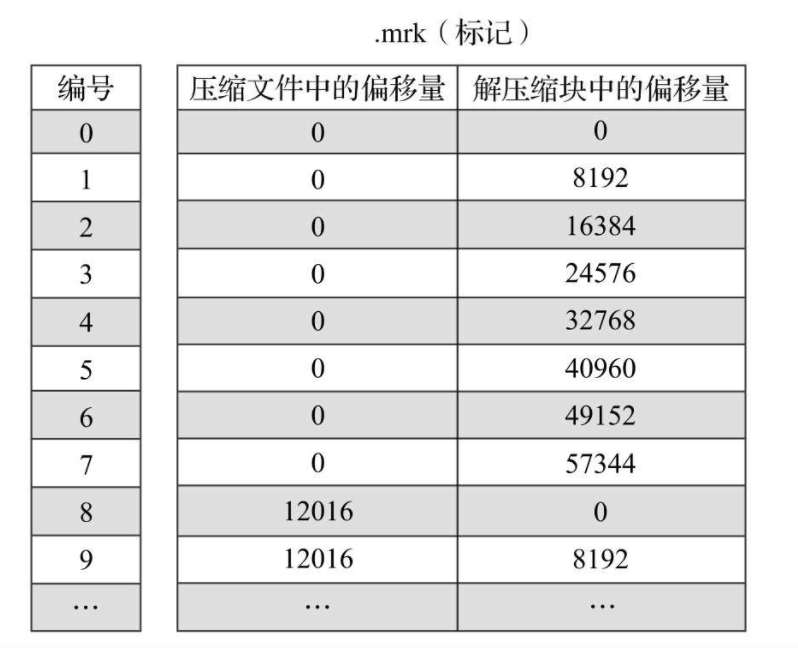
编号与markrange对应
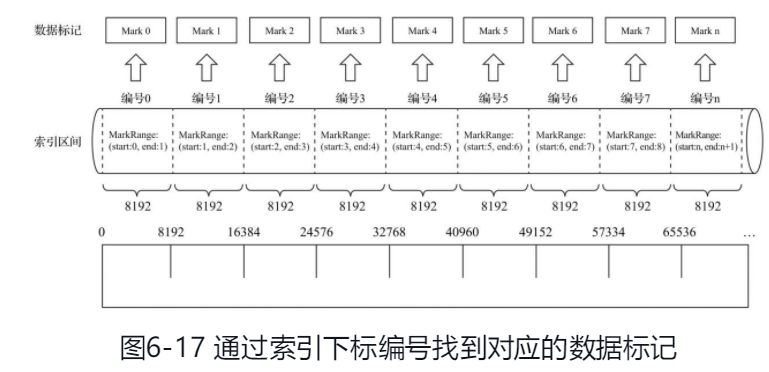
数据写入过程
生成分区目录,每一批数据写入都会生成一个新的分区目录,按照index_granularity索引粒度生成一级索引,mrk,bin文件
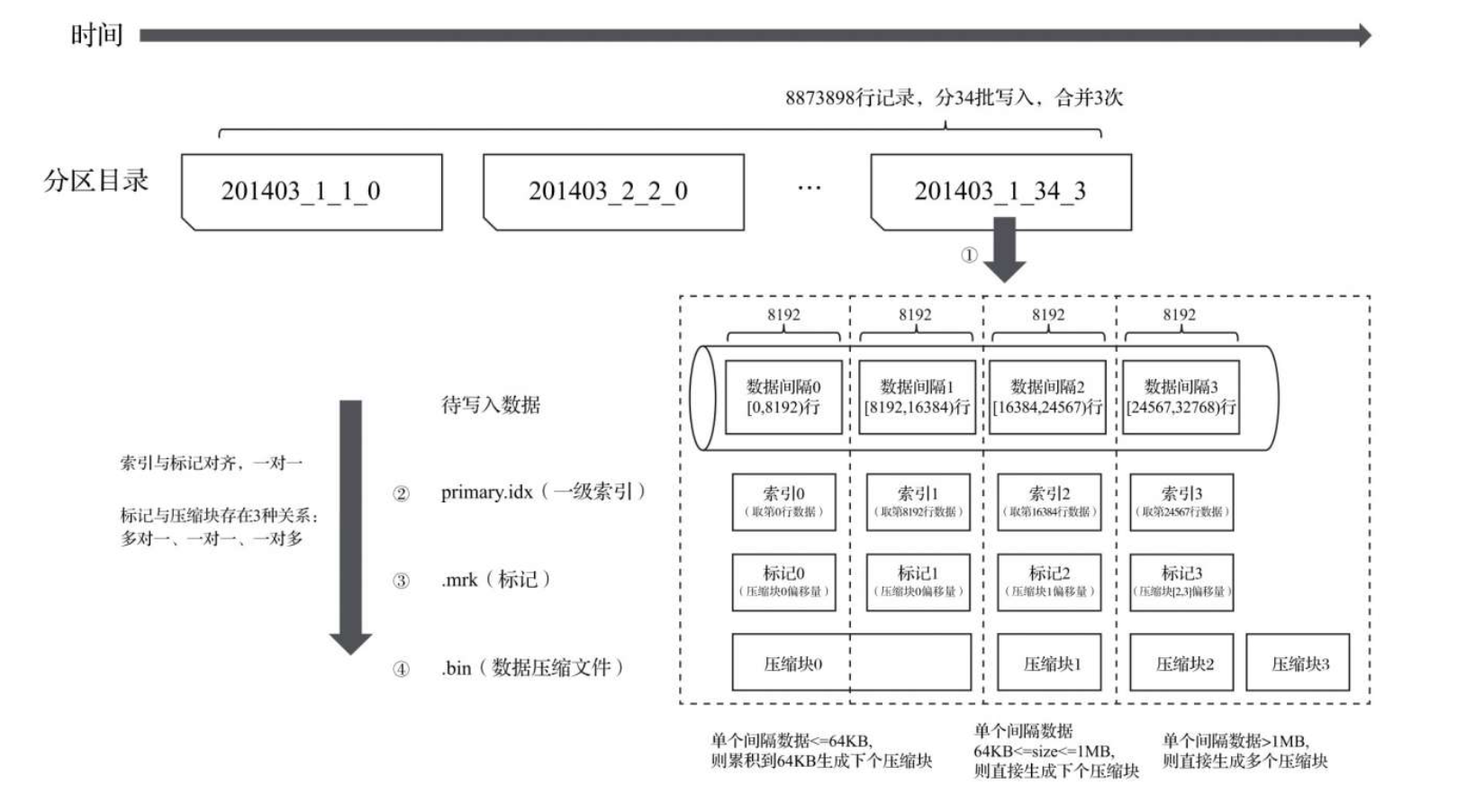
数据读出过程
update
ClickHouse的异步update机制。ClickHouse对update的执行是低效的,ClickHouse内核中的MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。ClickHouse的语法把Update操作也加入到了Alter Table的范畴中.
当用户执行一个如上的Update操作获得返回时,ClickHouse内核其实只做了两件事情:
- 检查Update操作是否合法;
- 保存Update命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;先查找到需要update的数据所在datapart,之后对整个datapart做扫描,更新需要变更的数据,然后再将数据重新落盘生成新的datapart,最后用新的datapart做替代并remove掉过期的datapart。
使用insert语句代替update语句。当需要对某一指定id更新数据时,就重新插入一条该id的数据.
使用MergeTree的变种AggregatingMergeTree.
AggregatingMergeTree继承自 MergeTree,存储上和基础的MergeTree其实没有任何差异,而是在数据Merge的过程中加入了“额外的合并逻辑”, AggregatingMergeTree 会将相同主键的所有行(在一个数据片段内)替换为单个存储
配合anyLast函数,替换每行数据为一种预聚合状态。其中anyLast聚合函数声明聚合策略为保留最后一次的更新数据.
insert buffer
默认情况下,每个单独的insert到MergeTree都会创建一个part,存储在文件系统上是一个单独的目录中,因此,向MergeTree进行插入最好是通过批量插入的方式进行.
将要写的数据缓冲到RAM中,定期将其刷新到另一个表中。在读取操作中,同时从缓冲区和另一个表读取数据。
1 | |
如果满足所有min条件或至少一个max条件,则将数据从缓冲区中刷新并写入目标表。
在写操作期间,数据被插入到num_layers数目的随机缓冲区中。或者,如果要插入的数据部分足够大(大于max_rows或max_bytes),则直接写入目标表,而省略缓冲区。
从 Buffer 表读取时,将从缓冲区和目标表(如果有)处理数据。
请注意,Buffer 表不支持索引。换句话说,缓冲区中的数据被完全扫描,对于大缓冲区来说可能很慢。(对于目标表中的数据,将使用它支持的索引。)
如果服务器异常重启,缓冲区中的数据将丢失。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!