X-engine
X-engine
abstract
introduction
网上电子商务交易有三个显著特征
The tsunami problem
从11月11日00:00:00开始,底层存储引擎的事务工作负载(反映为每秒事务与时间的垂直峰值)急剧增加,就像一场巨大的海啸袭击了海岸。
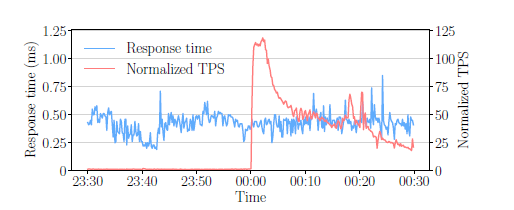
The flood discharge problem
存储引擎必须能够在处理高并发电子商务的同时,将数据从主存快速移动到持久存储(即,释放内存中积累的洪水)
The fast-moving current problem
数据库缓存中的热记录会不断变化,任何记录的温度都可能迅速地从冷/暖变化到热或热到冷/暖。存储引擎需要确保能够尽快从深水中检索并有效地存储新出现的热记录。
system overview
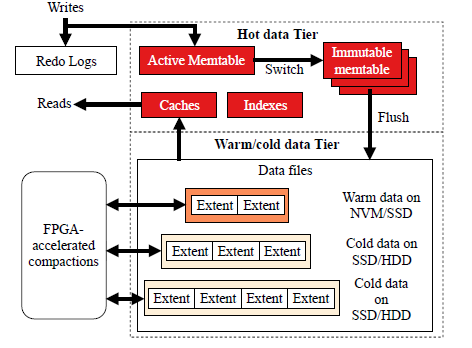
类似 lsm tree structure
detailed design
read path
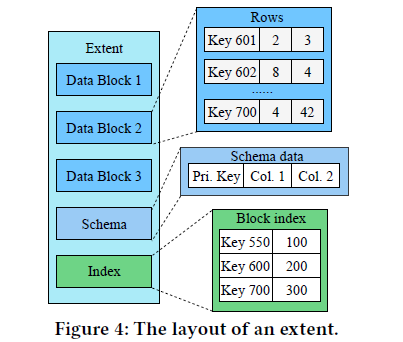
extent ,类似SSTable, 每个extent包含了若干data blocks,schema data,block index.
data block: row-oriented,schema data: the types of each column,block index: the offset for each data block.
an extent 2MB across all levels. (extents reuse during compactions)
当向表中添加新列时,我们只需要在新版本的新extent上强制使用这个新列,而不需要修改任何现有的extent。当查询读取具有不同版本schema的extent时,会与最新版本的extent一致,并在旧版本中填充记录的空属性的默认值。
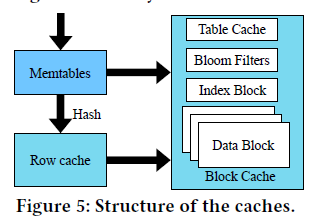
row cache for optimizing point lookups.
LRU cache replacement policy.
a point lookup missed the memtables, the key of the query is hashed to its corresponding slot in the row cache for matches.
只在行缓存中保存最新版本的记录,由于时间局部性,这些记录有最大的机会被访问。为了实现这一点,我们在刷新期间用行缓存中的新记录替换旧版本的记录,以减少flush可能导致的cache miss。
block cache以数据块为单位缓冲数据。它为miss行缓存或 范围查询的每个请求提供服务(所以图5 中指向block cache有两条路径). table cache包含指向相应区段的子表头的元数据信息。找到extent后,我们使用Bloom过滤器过滤出不匹配的key。然后,我们搜索索引块来定位记录,最后从它的数据块中检索它。
由于 spatial locality, block cache可以作为row cache的补充.
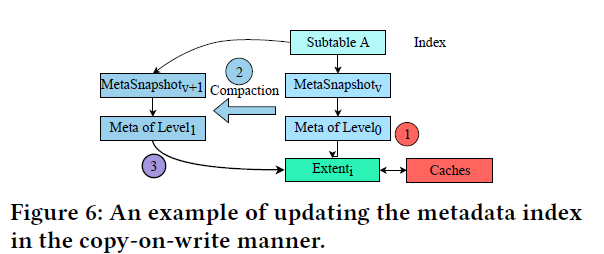
multi version metadata index ,reuse extent without actually moving in the disk.
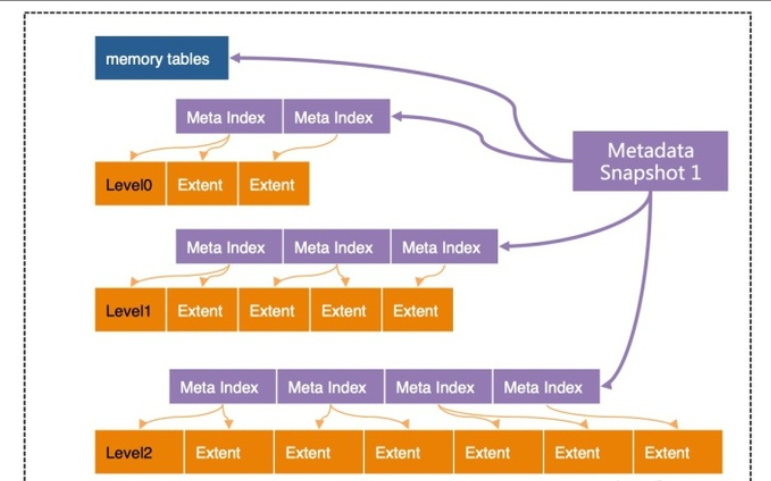
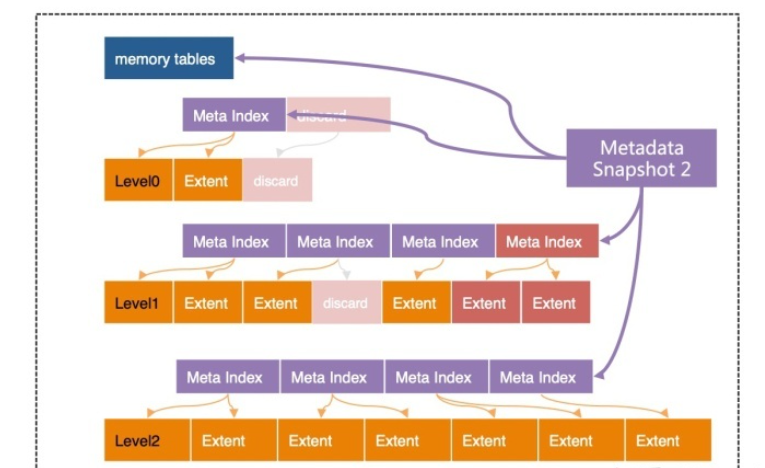
Incremental cache replacement
During compactions, we check whether the data blocks of an extent to be merged are cached. If so, we replace the old blocks in the cache with the newly merged ones at the same place, instead of simply evicting all old ones
reduces the cache misses by keeping some blocks both updated and unmoved in the block cache
如果不更新cache 而是简单的evict from cache,那么下次访问这些block时还会产生io.
write path
memtable lock free skiplist
the state-of-the-art implementation of the skiplist-based memtables has a performance issue when querying hot records. Frequent updates on a single record generate many versions. If a hot record matches the predicate of a query with interests in only the latest version, the query may have to scan many old versions to locate the requested one.
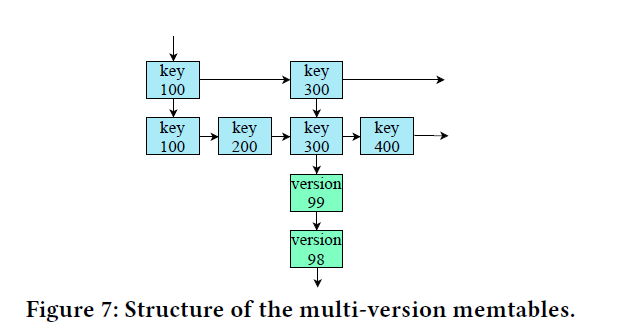
将同一记录的新版本垂直地附加到原始节点旁边,形成一个新的链表。减少扫描不必要的旧版本造成的开销
Asynchronous writes in transactions
避免one thread one transaction 写磁盘时的延迟,没有充分利用线程资源,在进行io时线程处于等待状态. 在一个大小为8的的队列中,只有一个线程在提交写,同时batch commit可以提高io.
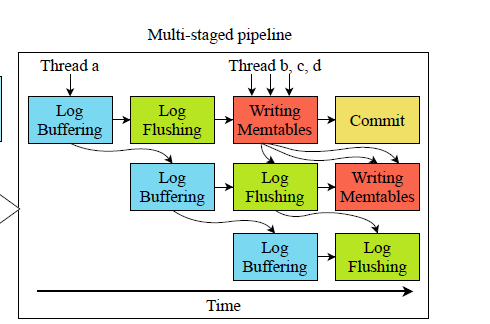
Multi-staged pipeline
- 在第一阶段,log buffering,线程从事务缓冲区收集每个写请求的wals(写前日志)到内存驻留日志缓冲区,并计算它们对应的CRC32错误检测代码。这个阶段包括计算和仅访问主存
- 在第二个阶段,log flushing,线程将缓冲区中的日志刷新到磁盘。刷新日志后,日志文件中的日志序号会上升。这些线程然后将已经被记录的写任务推到下一个阶段,
- writing memtables,多个线程并行地追加活动memtable中的记录。这个阶段只访问主存
- commits,所有任务完成的事务最终由多个线程并行提交,它们使用的资源,如锁被释放
第一个和第三个阶段访问主存中不同的数据结构,而第二个阶段写入磁盘。因此,重叠它们可以提高主存和磁盘的利用率。
由于在前两个阶段的数据依赖关系(log buffer 或者 log flush 需要保证顺序),每个阶段我们只安排一个线程。对于其他阶段,我们分配多个线程并行处理。从前两个阶段提取任务的操作是抢占式的,只允许第一个到达的线程处理该阶段。其他阶段是并行,允许多个线程并行工作。
flush and compaction
intra-Level0 compactions to actively merge warm extents in Level0
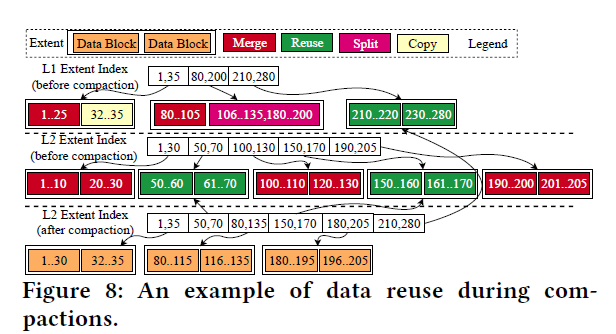
data reuse
在压缩过程中重用区段和数据块,以减少合并两个相邻层(即Leveli和Leveli+1)所需的I/ o数量。为了增加重用的机会并使其有效,我们将一个区段的大小减少到2 MB,并进一步将一个区段划分为多个16 KB的数据块。如果压缩过程中涉及到的某个区段的键范围没有与其他区段的键范围重叠,我们只需更新其对应的元数据索引,而不实际将其移动到磁盘上,就可以重用它。
Asynchronous I/O
压缩操作包括三个互不相干的阶段:
- 从存储中检索两个输入区段,
- 合并它们
- 将合并后的区段(一个或多个)写回存储。
第一和第三阶段是I/O阶段,而第二阶段是计算密集型阶段。我们在第一和第三阶段发出异步I/O请求。第二阶段是作为第一I/O阶段的回调函数实现的。当多个压缩并行运行时,第二阶段的执行与其他阶段的执行重叠,充分利用io。
FPGA
在X-Engine中区分不同的Compaction
- intra-Level0 Compaction,level 0 内部的compaction 不会进入level1
- Minor Compaction,在每两个Level之间合并,except the largest level
- Major Compaction,合并最大级和它上面那一级
- Self-Major Compaction,在最大级内进行合并,减少碎片,删除无用records。
阿里巴巴的一个在线应用程序tailored的配置示例。在这个应用程序中,有频繁的删除。当应该删除的记录数量达到其阈值时,将触发压缩来删除这些记录,并将这种压缩给予最高优先级,以防止存储空间的浪费。在删除之后,将对Level0内的压缩进行优先级排序,以帮助加快对Level0中最近插入的记录的查找。minor、major和self major分别按此顺序排列
compaction concurrent at the level of sub-tables
感觉sub-table的概念类似与clickhouse中的分区.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!