Workload-Driven Placement of Column-Store Data Structures on DRAM and NVM
DaMoN 2021 原文链接
abstract
研究列存储数据结构在 DRAM 和 NVM 的混合层次结构中的放置,目的是在不影响性能的情况下将尽可能多的数据放置在 NVM 中
提出一种启发式方法,利用轻量级访问计数器来建议哪些结构应该放在 DRAM 中,哪些应该放在 NVM 中
使用 TPC-H 的评估表明,超过 80% 的查询所接触的数据可以放在 NVM 中,几乎没有减速,而naively将所有数据放在 NVM 中会增加53%的运行时间
introduction
在本文中,我们研究了使用 NVM 来存储 SAP HANA 的读优化的列存储数据结构。
目标是将尽可能多的数据移动到 NVM,而不会对分析工作负载中的查询性能产生负面影响。
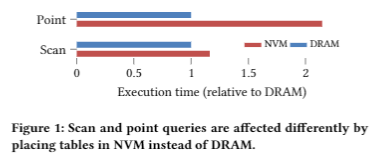
当数据放在 NVM 中时,扫描繁重查询的运行时间仅增加了 16%,而点查询的运行时间却减慢了 115%。这可能归因于顺序加载的较低延迟和高效的prefetch。由于 DRAM 和 NVM 上的点访问和扫描之间的性能如此不同,我们认为在决定是否应将其放置在 NVM 中时,考虑数据结构上的主要访问类型至关重要。为此,我们建议使用访问计数器在数据结构级别区分点访问和扫描访问,以指导放置决策.
background
SAP HANA
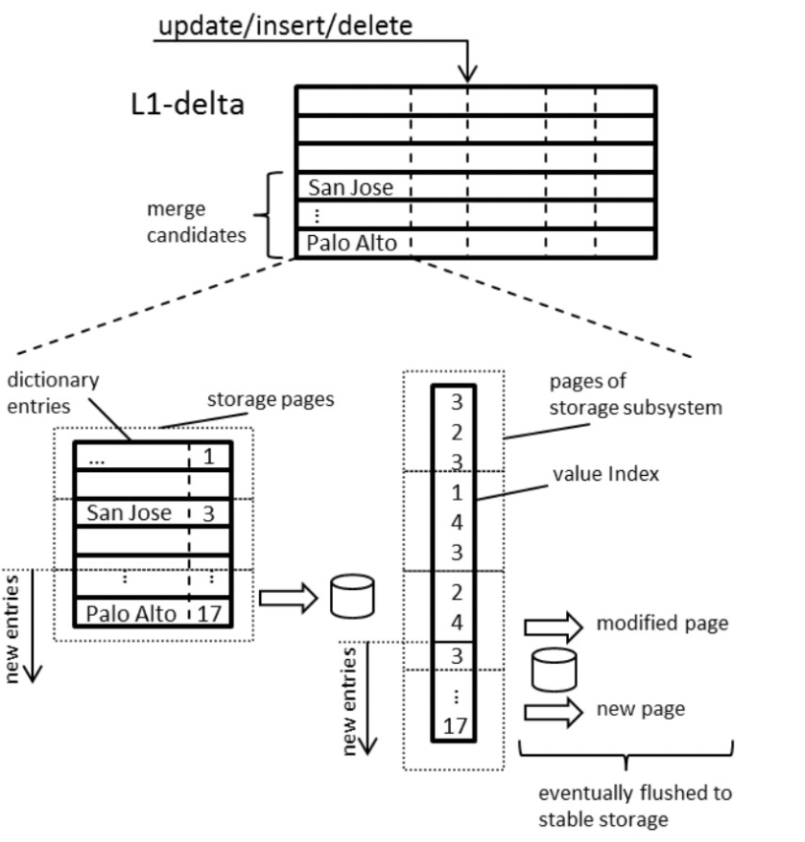
使用读优化的main fragment 和写优化的delta fragment 存储每个表。两者都会定期合并,通常是在增量超过特定大小时。我们关注main store ,因为它代表了大部分表数据,它采用domain encoding 进行数据压缩并加快访问速度。domain encoding 列由数据向量和字典组成。该字典包含已排序且唯一的原始列值。数据向量为列的每一行存储一个value id。默认情况下,数据向量是按位打包的,但也可以使用逻辑压缩技术(如run length 或稀疏编码)进行压缩。这可以伴随着重新排列表行,从而使整个表压缩变得更有效。字符串字典也可以被压缩以进一步减少内存使用。使用 SIMD 指令可以加速对数据向量的扫描。在查询执行过程中,访问数据向量和字典的方式主要有两种:获取过滤后的行集(SQL WHERE),首先在字典中搜索匹配值并生成一组值id。在许多情况下(例如,相等或范围谓词)可以利用字典的排序特性来避免对字典的完全扫描。然后通过扫描数据向量来获取与先前字典搜索产生的值 id 匹配的值 id 的行 id .第二个访问情况是需要具体化行值时,例如,用于投影、连接或聚合。在这种情况下,使用行 id 执行数据向量中的查找,这会产生一个值 id,然后在字典中查找以检索该值.
relate work
NVM in the storage layer
一些工作将 NVM 用作缓存层次结构中的附加层。
缓冲区管理方法基于其驱逐和上次访问页面时的迁移策略,并且由于策略的性质,可能会在 DRAM 和 NVM 之间复制数据。我们认为在 NVM 中存储数据是一个放置问题,其中数据位于 NVM 或 DRAM 中,并建议区分扫描和点访问数据结构以指导放置决策。虽然我们实现了缓冲区管理数据结构的放置以简化实现,但我们的结果可以转移到 SAP HANA 的内存结构中
**data management on multi tier hierarchies **
一些工作专注于跨内存层次结构在其他级别放置数据。
Bhattacharjee 研究具有 HDD 和 SSD 的多层存储层次结构可以有效地用于数据管理。他们根据对给定工作负载的随机和顺序访问磁盘页面的计数来估计访问时间节省,从而将数据库对象静态放置在 SSD 而不是 HDD 上。boissier 根据列上的访问模式主要是顺序还是随机,以列粒度在 DRAM 和二级存储之间做出放置决策。然后将不同的存储布局用于放置在二级存储中的数据。我们还在本文中区分了随机点和顺序扫描访问,尽管是将内存数据放置在 DRAM 或 NVM 中,而不改变存储布局。vogel 提出了 Mosaic,存储引擎可以将数据最优的放置在tier-less pool,用于基于磁盘的系统中的扫描繁重工作负载。我们旨在为内存中存储提供类似的最佳放置建议.
placement policy
首先讨论我们如何在 NVM 中放置数据,然后是一个初步实验来评估在 NVM 中放置数据的可行性。然后,我们使用 SAP HANA 中的两个主要数据结构数据向量和字典上的访问计数器来识别主要访问类型。最后,我们基于访问计数器推导出对各个列的数据结构进行放置决策的启发式方法
facilitating Placement on NVM
我们通过使用 NVM-backed layer 扩展 SAP HANA 的buffer cache 来实现数据结构放置。
当从buffer cache 中请求page时 就相当于该page在NVM中.
Placement Based on Data Structure Type
为了初步了解将 SAP HANA 的main store放置在 NVM 中的可行性和潜力,我们使用来自 TPC-H 基准测试的查询测试了四种简单的放置策略,sf为 100。四种初始策略是:DRAM Only(),即所有数据放在DRAM中,NVM Only(), 数据向量在NVM()中,字典在NVM()中。请注意,除了数据向量和字典之外,NVM Only 策略还在 NVM 中放置索引。
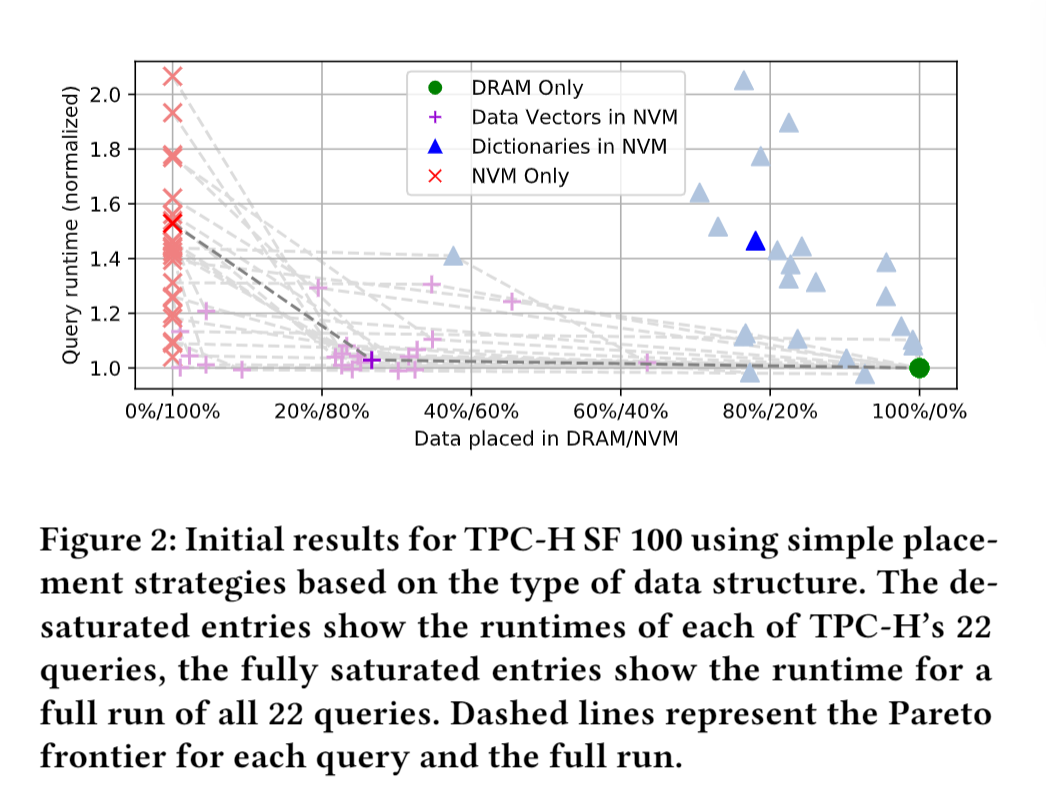
只有查询实际读取的数据才会加载到缓冲区缓存中,因此查询未触及的列(例如,L_COMMENT)不包括在内存使用统计中。
在许多情况下,NVM 可以容纳超过 70% 的数据量,查询速度下降不到 20%。虽然仅将数据向量放在 NVM 中已经产生了非常好的结果,但另外将选定的字典放在 NVM 中可能允许在类似性能下更低的 DRAM 使用率。在下文中,我们因此探索了更细粒度的数据放置策略,该策略还考虑了工作负载特征,特别是单个列上的访问模式。
analyzing access types
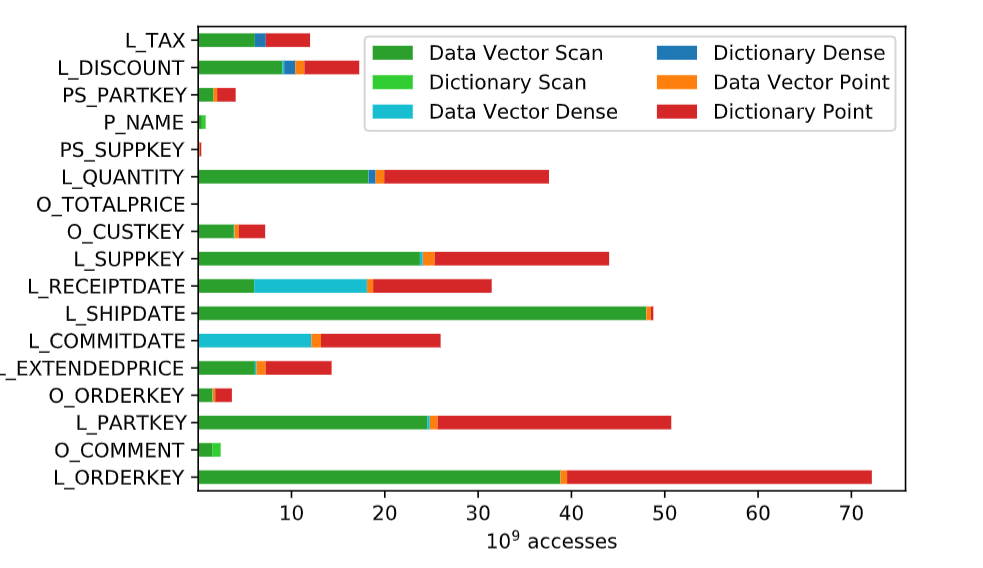
考虑在两个主要数据结构(数据向量和字典)上实现访问计数器。这些计数器代表访问数据结构条目的总数。为了能够放置在列 和 数据结构粒度上,我们分别为每一列收集访问计数器。正如我们之前已经确定点访问和扫描之间 NVM 的显着性能差异,我们区分这两种访问类型的计数器。对于点访问, 还会跟踪密集点访问(dense point accesses)。如果点访问在数据结构最后访问的条目之前或之后读取元素,则被认为是密集的。这种区别很有用,因为密集点访问构成了比真正的随机点访问更像扫描的访问模式,当具有这种访问模式的数据放置在 NVM 中时,这应该会导致不太明显的减速。我们只计算对每个数据结构的访问总数,因为我们目前只对在数据结构粒度上做出放置决策感兴趣。我们指出每个数据向量和每个字典只存在一组计数器(三个整数)。计数器也是惰性更新的,即,如果连续发生多次访问,这些首先由计划运算符在本地聚合,并仅添加到相应数据结构的计数器一次。因此,维护计数器的性能和空间开销可以忽略不计.

我们观察到数据向量主要通过密集点访问或scan,而字典主要使用点访问进行访问。字典也几乎从不扫描。
鉴于我们预计将数据放置在 NVM 中对扫描的影响较小,这与图 2 中的结果相匹配,在图 2 中,我们观察到主要在将字典放置在 NVM 中时会出现主要减速
Placement Based on Access Counters
根据对列的访问来放置每列的数据向量和字典,目的是在 NVM 中放置尽可能多的数据,同时尽可能少地降低性能。对于启发式,我们考虑两个主要因素:首先,在所有 TPC-H 查询的完整运行中,超过 70% 的所有访问都是类似扫描的,并且我们还发现这种访问模式表现出类似的DRAM 和 NVM 上的性能,而随机点访问模式会导致将数据放入 NVM 时的性能损失。因此,启发式中的一个因素应该是数据结构的扫描与点访问比率。其次,我们发现许多内存消耗最高的列很少被访问。
将这些列的数据向量和字典放置在 NVM 中,而不管它们的扫描与点访问比率如何
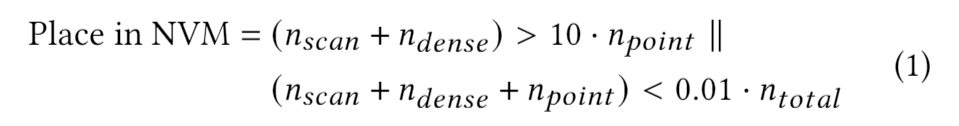
scan,点访问密集型或访问总数比较小放在NVM.
evaluation
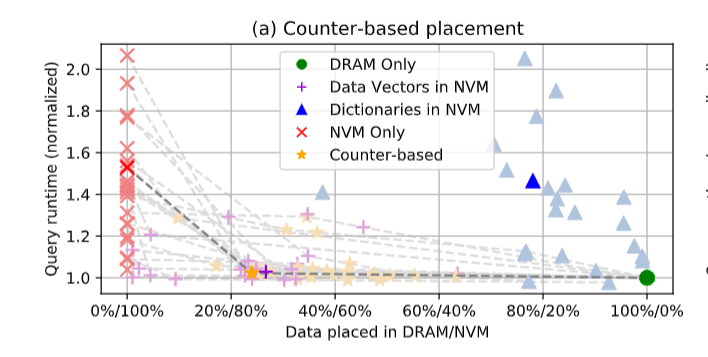
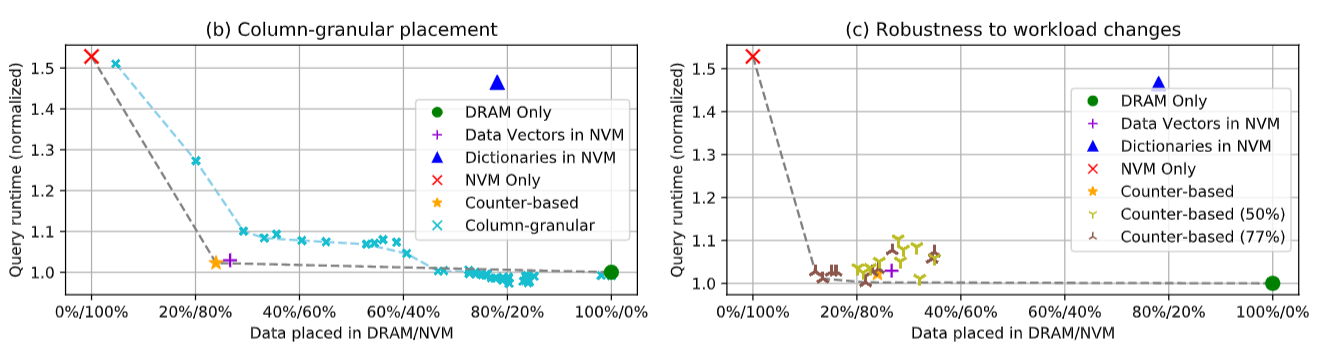
以数据结构粒度放置要比按列粒度放置优
discussion
水平分区数据的更细粒度放置也可能导致进一步改进的结果
评估其他工作负载将是可取的,例如,具有大量点查找的混合 HTAP 工作负载,以确定在这种情况下 NVM 对主要数据的适用性,并特别评估所提出的启发式方法的有效性
数据压缩和数据放置之间的交互,或者在查询优化期间考虑数据所在的位置。
如何或是否应该向用户展示像这里介绍的那样的数据放置替代方案。虽然一种选择是提供数据放置作为调整旋钮或提供放置顾问,但“自动驾驶”方法可能更需要系统自主做出这些决策而无需用户干预。
summary
对domain encoding 的系统比较有用吧, 观察到 dictionary 的访问模式和 vector的访问模式不同, 于是按数据结构粒度进行数据的放置(NVM or DRAM). 提出的公式就直接硬编码了一些参数, 以及实验只是在tpch上进行的. 在NVM上的数据结构的布局似乎也没有redesign.实验中找到的策略也不是最优的.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!