C-store
A Column-oriented DBMS
abstract
introduction
优化更新和优化读的数据结构之间存在矛盾。比如,当数据是按条目到达顺序存储时,可以在列的末尾以批处理或事务方式有效地插入新数据项。但是,这样读的代价会比较大。然而,以非数据到达顺序存储将使插入的代价昂贵。
C-Store从一个全新的角度解决了这个难题。将一个read-optimized的列存储和一个面向更新/插入的writeable store组合在一个系统中,由tuple mover连接。在top level,有一个小型的writeable store(WS)组件,它的体系结构支持高性能插入和更新。还有一个更大的组件称为read-optimized store(RS),它能够支持非常大量的存储。RS只支持一种非常受限的插入形式,即记录从WS批量移动到RS,这是tuple mover要做的。
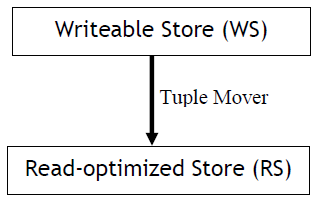
查询必须同时访问两个存储系统中的数据。插入被发送到WS,而删除必须被发送到WS。在RS中标记,以便稍后由元组移动器清除。更新实现为插入和删除。为了支持高速tuple mover,通过高效的有序合并方法将元组从WS批量移动到RS。
features of C-Store
- 一个混合架构,其中WS针对频繁插入和更新进行了优化,RS针对查询性能进行了优化。
- 表中的数据以不同顺序在几个overlapping projetions中冗余存储,以便使用最有利的projection来解决查询。
- 使用多种编码方案中的一种高度压缩列。
- 面向列的优化器和执行器,具有不同于面向行系统中的原语。
- 使用足够数量的overlapping projections,通过K-safety实现高可用和改进性能。
- 使用快照隔离以避免2PC和锁。
C-Store在物理上存储多组列集。在一个group中每个列按某些属性排序。按相同属性排序的列组称为 projection ;同一列可能存在于多个投影中,可能按每个投影中的不同属性排序。多个排序器可以优化查询。
在这里可以看出projection的概念和通常的projection不同。
存储overlapping projections进一步提高了性能,即使某个服务器发生故障,也可以访问数据。我们称能容忍K次故障的系统为K-safe。
data model
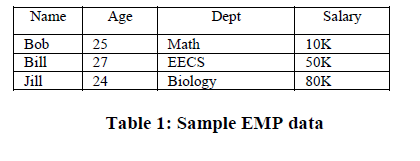

将排序键附加到由竖线分隔的投影上来指示projection的排序顺序。

每个projection horizontally划分为1个或多个segment,segment被赋予一个Sid。在一个projection中基于sort key划分segment。
storage key在RS中编号为1、2、3,并不是物理存储的,而是从列中的元组的物理位置推断出来的。storage key在WS中物理存在,并以整数表示,比RS中任何段的最大整数storage key都大。
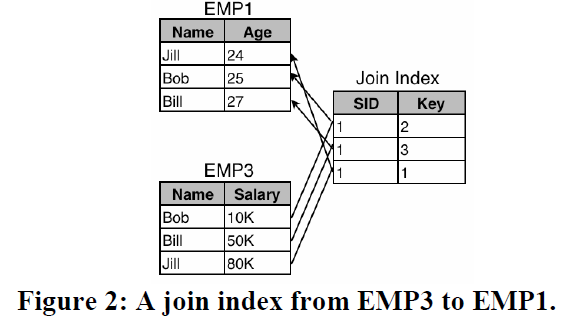
join index (sid, storage_key)
RS
encoding
self order the column ordered by values in that column(按列中的值排序,即该列在sort key中)
foreign-order by corresponding values of some other column in the same projection(该列不在sort key中)
self order few distinct values:三元组序列(v, f, n)表示,v是存储在列中的值,f是v在列中第一次出现的位置,n是v在列中出现的次数。
foreign order few distinct values: (v, b), v是存储在列中的值,b是一个位图,表示该值存储在哪个位置
- 0,0,1,1,2,1,0,2,1, we can Type 2-encode this as three pairs: (0, 110000100), (1, 001101001), and(2,000010010)
Self-order, many distinct values:将列中的每个值表示为与列中前一个值的增量。
- 1,4,7,7,8,12 would be represented by the sequence: 1,3,3,0,1,4
Foreign-order, many distinct values: leave the values unencoded
WS
WS也是一个列存储,实现了与RS相同的物理设计。因此,WS中存在相同的projection和join index。但是,存储表示形式有很大的不同,因为WS必须以事务方式有效地更新。
SK 显示存储
WS的水平分区方式与RS相同,因此RS segment与WS segment之间是1:1的映射。
假设WS size比较小 不压缩; 直接表示所有数据。因此,每个projection使用b -树索引,以保持逻辑排序键顺序。
WS projection中的每一列都表示为(v, sk),这样v是列中的值,sk是其对应的storage key。每个对在storage key上用b树表示。每个projection的sort key被另外表示为(s, sk),这样s是一个排序键值,sk是描述s第一次出现的storage key。同样,这个结构表示为sort key上的b树。要使用sort key search,可以使用后一个b -树查找storage key,然后使用前一个b -树集合查找记录中的其他字段。
storage management
projection中的一个segment中的所有列存储在一个服务器节点上。join index和segment存储在一起。ws和相同key range的rs存储在一起。
tuple mover
将创建一个新的RS segment,我们称之为RS’。然后,它从RS段的列中读入块,删除delete record vector值小于或等于low water mark的任何RS项,并合并来自WS的列值。然后将合并的数据写入新的RS段,该段随着合并的进行而增长。这种old master/new master将比就地更新策略更有效,因为基本上所有数据对象都将移动。需要维护join index.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!